Revision versioning with git
Recently at work we made the switch from subversion to git for our revision control software. I could explain why we made the jump, but you really just want to grab a beer and watch Linus’s talk on git (you do have an AppleTV to let you watch YouTube on the telly, right? ;).
Moving to git is not a decision to be taken lightly. It requires a move away from a trusted system, and everyone has to learn new tools and a slightly new work flow. However, in our experience, the effort has been worth it, and despite git’s reputation for being difficult to use, I find it’s a bit of a sheep in wolf’s clothing if you just give yourself time to work through the various how to guides on the web rather than trying to apply your cvs/subversion/whatever knowledge to git.
One change that is interesting that we had to solve was the loss of an obvious numbering scheme for comparing checkouts from the tree. I came up with a solution for CamVine, and I’ve had comments that this is a common issue, so I thought I’d take a moment to express our solution here. There’s even a little code to help you along :)
So, one of the nice features with subversion was that with every commit to the repository you got a new revision number for that commit that was one more than the last – the first commit was numbered 1, then the next commit 2, and so on. This meant that when you installed the software you could tag it with the commit number to know exactly what version you had. So, we’d label software with names like 1.2-r3456 – that is commit 3456 for version 1.2 of the software. Indeed, tools such as the popular Python setuptools encouraged you to do this.
However, with git commits do not have nice revision numbers – it sort of doesn’t make sense in git given its internal structure. Instead you get a SHA1 hash of the commit as a unique way of identifying that commit. I’m not sure about you, but naming your releases 1.2-r 880df0c29f83937c6b02b72180e1742d159fca81 seems less useful. I certainly can’t use it for automatic updates, as I can’t rely on the ordering of the hashes. We needed another solution.
Instead I came up with the following simple method that seems to do the job at Camvine. The below diagram attempts to show our repository structure as it grows. We have a main continuing development branch that always represents the latest and greatest code for a particular project, and is where most the fun happens. However, from time to time we commit a development branch as a particular version, and at that point we have a fork – the main development branch continues on to the new version, and we also fork a maintenance branch to which bug fixes are applied.
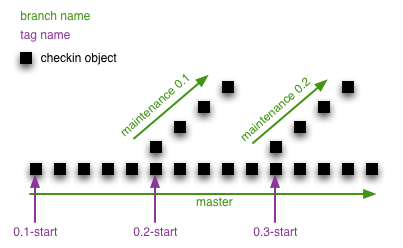
The solution I came up with for getting version numbers is very simple – rather than tagging releases when they’re finished, you tag the start point – either on the first commit to the repository or the commit just after you’ve forked for a release. You can see this in the tags in the diagram. Now, to get a simple increasing revision number for a particular commit anywhere in the tree you take the object you’re interested in and count the steps back until you hit a version start tag, and you’re done.
For example, in the diagram above the latest and greatest revision is 0.3-r5, whilst the latest bug fix release to 0.2 is 0.2-r9. In the build scripts for all our projects I’ve inserted a bit of python that works out current head object, and from that goes back and returns a version number and a revision number, ready for building python eggs, debian packages, whatever – that code can be found here.
- Next: Dad's Barmitzvah
- Previous: Racing history
- Tags: Geek